
Introduction
In this article, we will learn how to find and remove duplicate records in SQL.
According to database design best practices, a SQL table should not contain duplicate records. However, sometimes we need to work with databases where these rules are not followed or exceptions are possible when these rules are bypassed knowingly.
Below is an example of StudentInfo table with some duplicate records:

To delete the duplicate rows from the table in SQL, you need to follow these steps:
DELETE FROM StudentInfo WHERE ID NOT IN ( SELECT MAX(ID) FROM StudentInfo GROUP BY [Name], Age );
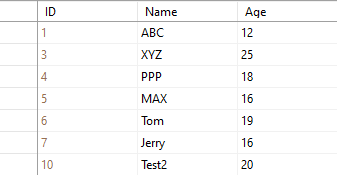
StudentInfo table has no duplicate records after executing the above query:
Also, check How To Create User In SQL